Summary
I used python to scrape a long-running blog that rips and posts cassette tapes, and then uploaded everything to a collection at the Internet Archive. Currently 3600+ tapes and counting (the blog is still going and I'm still scraping!).
Terminal Escape

Terminal Escape is a blog that has been posting a new rip of a cassette tape every day since mid 2009. The nearly 5000 posts by the wizard represent a massive documentation of punk, hardcore and related music, both in North America and internationally. Many small-run tape demos from contemporary bands are found on Terminal Escape, alongside rarer bootlegs, live tapes, and cassette oddities the author has picked up in his years of traveling, touring, and tape trading.
MP3 Blogs
Terminal Escape is one of the last remaining holdouts in the "mp3 blogspot" scene that was more prominent in the early-mid 2010s. Some of these blogs would essentially be curated music-piracy sites, posting download links for pirated mp3s. Most of these blogs in my bookmarks were at least dedicated to showcasing lesser-known or more underground releases that would be harder to find even on other file-sharing platforms at the time. But the most interesting of these blogs were certainly ones like Terminal Escape where the authors were actually ripping tapes and vinyl records themselves, often providing a digital copy of a release that was rare, out of print, and not really available anywhere else. A download link was usually accompanied with some context about how the recording fit into a scene or oeuvre, or how the collector came upon it.
Blogspot provided an easy way for less tech-savvy users to host a blog for posts like this, but doesn't provide any file hosting so these blogs always relied on free file-hosting services like mediafire or zippyshare (or any of a number of even sketchier sites with the same model). Sadly, these free file-hosting services have no incentive to keep download links live forever, and ofter links would go "dead" because they were identified as likely piracy, or were deemed to be "abandoned" or because the entire service decided to shut down with little notice (the zippyshare service shut down with little notice just a few months ago, leaving countless dead download links all across the internet). Many of the blogs themselves were shut down or went dark overtime, taking all their download links with them. Some that are still running have shifted to using Google Drive to hose their download links which seems obviously precarious.
For example, one blog I used to check for rare ska, rocksteady and dub is now totally gone: You & Me On A Jamboree (archive link). Cut & Paste was another well-known blog that posted discographies for underground punk and hardcore bands but used zippyshare exclusively for download links, so they are now all completely lost.

Terminal Escape is still going, with the wizard still posting new tapes every day, but he's not able to go back and update every old link that has gone dead. Already in the archives there are some 1000+ download links (of original rips!) that have gone dead.

Terminal Esc(r)ape
I wanted a python project to do to beef up my scripting/coding skills, so I decided to work on a tool to scrape all the still-live download links on Terminal Escape. Building a web scraper is a classic entry level python project, and I knew this would be a bit more challenging for me since I would have to handle various sketchy file-hosting services and grabbing lots of different metadata from blogposts. At first I thought that this would be a fun personal project. I could have my own personal copy of all the mp3s on Terminal Escape, put it on my iPod and set it to shuffle, never being bored or disappointed. Knowing the history of such blogs it also seemed useful to make an archival copy of everything that I could share with friends at some point so I knew I wanted to grab the text of the blog posts alongside the mp3s (thinking perhaps I would embed the text in the ID3 tags, or maybe just doing a simple website scrape).
Then I realized that The Internet Archive has a python library that can be used to automate uploading files to the archive. Knowing that, I immediately decided I should also use python to script uploading everything to The Internet Archive, which is the perfect forever-home for the historical collection that the output of Terminal Escape represents. No more dead-links! The Internet Archive also makes everything nice and searchable, and audio files and be played in-browser. There is already quite a bit of "punk" and related content there, especially large zine libraries like the full run of MRR. But there's also less than you think! There are a few users ripping and uploading underground tapes but most of what has been posted on Terminal Escape is not there. And the accumulated collected of everything the wizard has posted, along with his commentary really does represent a huge and relatively well indexed and contextualized archive of a large cross-section of many punk/hardcore/underground scenes. Preserving that archive is important! So I got the blessing of the wizard himself and got to work.

Building the scraper
There are certainly already website scraping scripts, written in python and other languages, that would dig through a blogspot.com blog, and aggressively grab every single download link. However, I didn't think there would already be a tool that would parse each blog post and collect all the extra metadata I wanted (not just the .zip archive) and store it all neatly in a way that would make uploading to archive.org easy. After I started uploading items from Terminal Escape to the archive, it caught the attention of another archivist who uploads massive discography zip archives. They used one of these "industrial" scrapers to grab all the .zip archives in one colossal archive item containg every .zip archive they could grab - which is great, but all the extra tagging, metadata and blog post text is missing! The individual tapes arn't indexed in the archive, nothing is tagged, and you browse and listen in your browser! I really wanted to do a proper archiving job, uploading each tape-plus-blog-post as an individual item to the archive
For each post on Terminal Escape I wanted to collect:
- The text of the post - each post includes commentary from the wizard, which can include his history with the tape or band, how he came by the tape, a review, and additional context placing the band or release in the broader genre or scene it's coming from
- The tags of the post - seemingly every post on Terminal Escape it tagged with genres and locations/countries associated with the post
- Images. Most posts are accompanied by images, usually scans of the cassette
- Links. Often there are links to related posts on Terminal Escape, the band's own website, or other related sites
- Other metadata like the date and title of the post
- All the mp3 files!
Figuring out how to parse through each post with BeautifulSoup was very straightforward. For each post, I created a new folder and populated it with the images and a .json file containing all the post's metadata.
Scraping Download Links
I did some random sampling through the history of Terminal Escape to identify all the different free file-hosting services the blog has used over the years. Often these services don't give you a direct download link, but either redirect you to a live link or require you to push a button on the page to get a download link. In every case, I wanted to grab the direct download link so I could pass it off to a python function to handle the actual download neatly. The services used on Terminal Escape are:
- opendrive.com
- box.com
- mediafire.com
Opendrive
There were several different url patterns for opendrive:
https://od.lkhttps://opendrive.comhttps://terminalescape.opendrive.com
But for all of them getting the actual download link was pretty straightforward. It was either a direct link to the .zip file, or I just had to use requests to follow a redirect, and then use BeautifulSoup to parse out the direct download link. I needed some basic error checking since there are dead download links, or links with typos.
Box.com
Box.com was trickier because this site required you do click an actual download button for the download link to become available. In order to scrape those things, I needed to use Selenium WebDriver. This was a bigger challenge for me, since I had worked through many "build a scraper with BeautifulSoup" tutorials, but never used anything more sophisticated. Selenium WebDriver and the associated python libraries allows a python script to automate an actual browser. Next level scraping. Selenium would allow me to automate pushing the "Download" button on a Box.com download page.
I was a bit wary of the process of managing the drivers for Selenium, so I also used the webdriver-manager library. It worked very well!
I just had to go through a little bit of trial and error to make sure the timeout is long enough for all the elements to load, then find the correct element in the page for the "Download" button, click the button, and then intercept and abort the actual request clicking the button initiates (while saving the direct download link to the file).
mediafire
It turns out every single mediafire download link on Terminal Escape is already dead. It mostly appears in older posts, and at some point the wizard stopped using it. I still wrote in a way to handle (working) mediafire links because I expected I would run this script against other blogs hosted on blogspot that might still have a few live mediafire download links. Mediafire links also redirect you to a download page, and then the download is initiated by some javascript in the page. For my scraper, I had to follow the redirect, and then use BeautifulSoup with a bit of regex to pull the url to the direct download out of the <script> tag.
Downloading
I ended up with a few download links for images and zip archives for each post and I wrote another python function I could throw all these links at. One thing that was tricky was checking if there was a Content-Description header returned with the GET request to the direct download link, and if that Content-Description contained a useful filename. Whenever possible I wanted to save the file with the actual filename the wizard had saved it under, but I ended up down a small rabbit hole since not all these download sites respect the same format for the Content-Description header. A bit of hacky scripting made it work for all the cases I ran into.
I also adapted some code from helpful strangers online to give myself nice progress bars in the terminal as each file downloaded.
I also had the python scraper decompress every zip archive. It seems that the wizard is a Mac user, since every zip archive included a useless __MACOSX directory. I wish I had written in a line to delete those directories, but as it stands I had to later write a bash script to scrub them all lest I accidentally upload them to The Internet Archive.
#!/bin/bash
for dir in scrape/* ; do
rm -r $dir/extracted/__MACOSX/
done
The Big Scrape
It took a few false starts, but eventually I added in enough error-catching and logging so that the scraper could run without interruption. Then I let it loose. I actually ran the bulk of it over a few sessions, but I was able to scrape the entire blog without issue. Here are the stats:
From the first post on the blog on June 16 2009 until a recent post on April 30 2023:
- 4764 posts scraped
- 1073 dead links
- 3691 successfully scraped (77% of posts)
- 139 GB of uncompressed mp3s + images
- 35056 mp3s
Uploading to The Internet Archive
I have undertaken previous projects to upload collections of items to the Internet Archive before, but this was the first time I did anything automated or at this scale. I decided to create a new account for this (and future?) projects. The documentation for the internetarchive python library makes it very easy to get started, although I did find the documentation lacking when it came to helping me implement more complicated features of the API.
A big difficulty I had was testing, since some trial and error is necessary (at least for me) to make sure the uploaded items are created properly. The Internet Archive offers a test collection where items are automatically deleted after 30 days that anyone can add to. However, every item in the Internet Archive has a unique identifier, and as far as I can tell these identifiers can't be re-used even after an item is deleted. Every test upload requires a unique identifier, and if you try to do some testing by creating items in the test collection but using throw-away identifiers like n00q-test-01, n00q-test-02 then your uploads will be flagged as spam and blocked. This was a bit of frustration for me, but I did eventually get enough tests done to confirm everything was working.
Building a script to automatically upload my scrapes was relatively easy. The biggest challenge was creating a unique and useful identifier for each item. In most cases, I could pull the artist and album off of ID3 tags (using the TinyTag python library) and use those to derive an identifier like Artist_Album. There were a lot of posts which would be a few tapes from the same band, like a demo packaged with a newer release. In those cases, I might try to use just the Artist name or the title of the post. Then there were compilations, posts where the mp3s were not tagged, and other edge cases. I sorted out every possible situation and had the script come up with the best identifier. Mapping all the metadata to Internet Archive item metadata was also easy, to the tags from each Terminal Escape post became the "Topics" on the Internet Archive, I listed Terminal Escape as the "Contributor", year of release if it was present in the ID3 tags, and included the test of the original Terminal Escape post as the description with a link back to the original post.
The only errors I ran into once the upload script was running had to do with the item identifiers. Bands often have unusual names. Some of the generated identifiers ended up being generic words or phrases that were already occupied by other items in the Internet Archive (eg yogurt). It also appears that the Internet Archive has a list of words or phrases that are reserved or blocked from being item identifier's and I ran into a few of these as well. I ended up with around 100 items where I had to manually specify an identifier.
The Collector Will Collect
By default, new uploads to the Internet Archive are just dumped into a "Community Collection", but with a project like this it makes sense to have all the items groups together in a proper collection. The Hip Hop Mixtapes collection is an example of a similar large collection in the Internet Archive. You have to request a new collection be created for you, essentially by e-mailing in and making your case. I started uploading, and send in me request. I had to bump them once but was finally granted the Terminal Escape Collection.
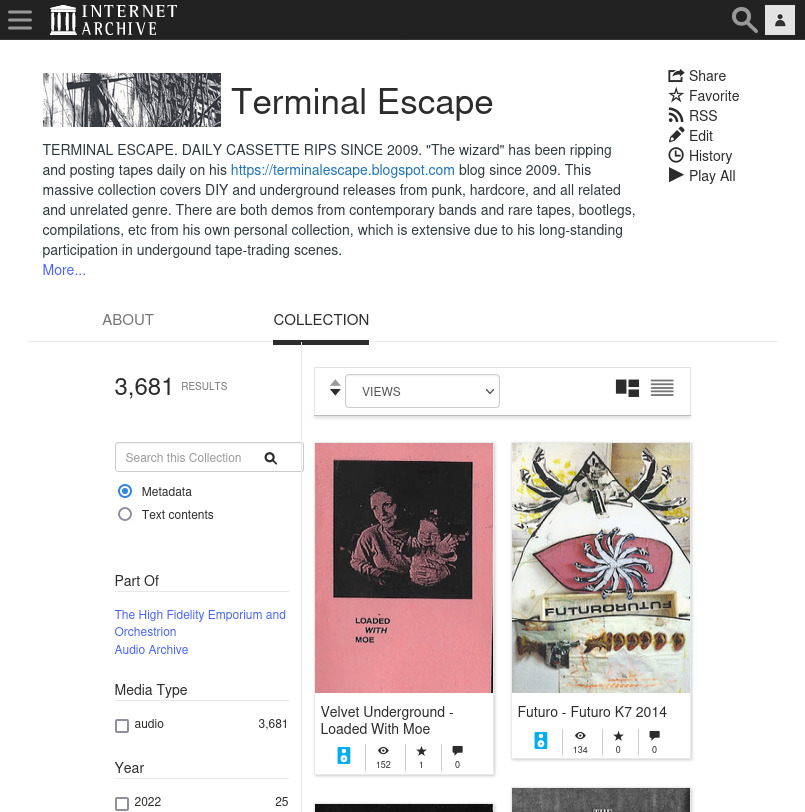
Once everything was up in a collection it felt really good. The Internet Archive has a built in media player and while it's not as pretty and slick as something like bandcamp or spotify, it works just fine, it lists and plays all the songs properly, it shows the included art alongside it. Browsing and listening to the tapes in this collection is so much easier than digging through posts on the original blog, but the text of the original blog post is included on each item, so you still get to benefit from the wizard's commentary and context.
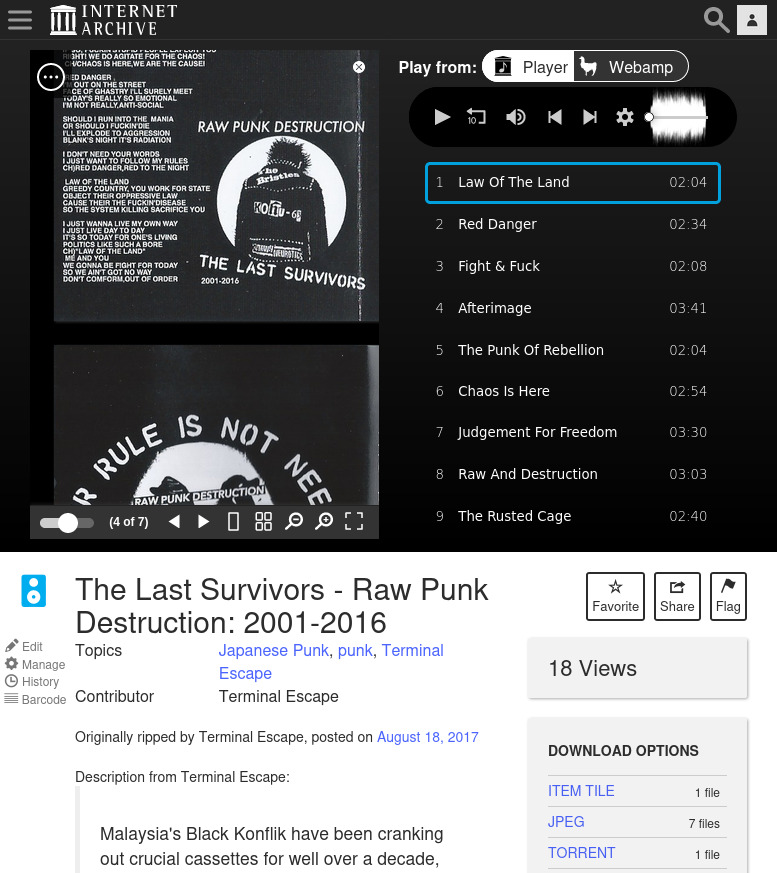
The Internet Archive also has powerful search and filtering, and because the wizard was quite diligent at tagging everything, it's extremely easy to quickly filter by year, location or genre.
Next
The wizard is still posting every day, so I can run the scrape script and the upload script at some interval (monthly)? to dump all the new posts onto the archive. It might be cool to try and automate that process on a server, however I think I would still want to babysit and review the uploads manually.
There are also many other mp3 blogs that are still up but abandoned with their download links slowly going dead, just waiting for Google to pull the plug. The wizard operates another blog, Escape is Terminal which I've already started scraping without issue. I also ran the script against two other similar mp3 blogs in my bookmarks and managed to grab all the live links along with the respective author's commentary and I plan to upload all that once I'm done with Escape is Terminal.
I would be interested in helping archive other similar blogs, especially if they are posting original rips of rare music (ie not just posting pirated content). If you have a suggestion of an mp3 blogspot site that should be archived in this manner, contact me.